TL;DR
In a joint effort between PyTorch and Nebius, we enabled training DeepSeek-V3 Mixture-of-Experts models (16B and 671B) on a 256-GPU NVIDIA B200 cluster using TorchTitan. We evaluated two orthogonal optimizations on top of a BF16 baseline: MXFP8 training (via TorchAO) and DeepEP communication acceleration (via DeepEP). The highlights:
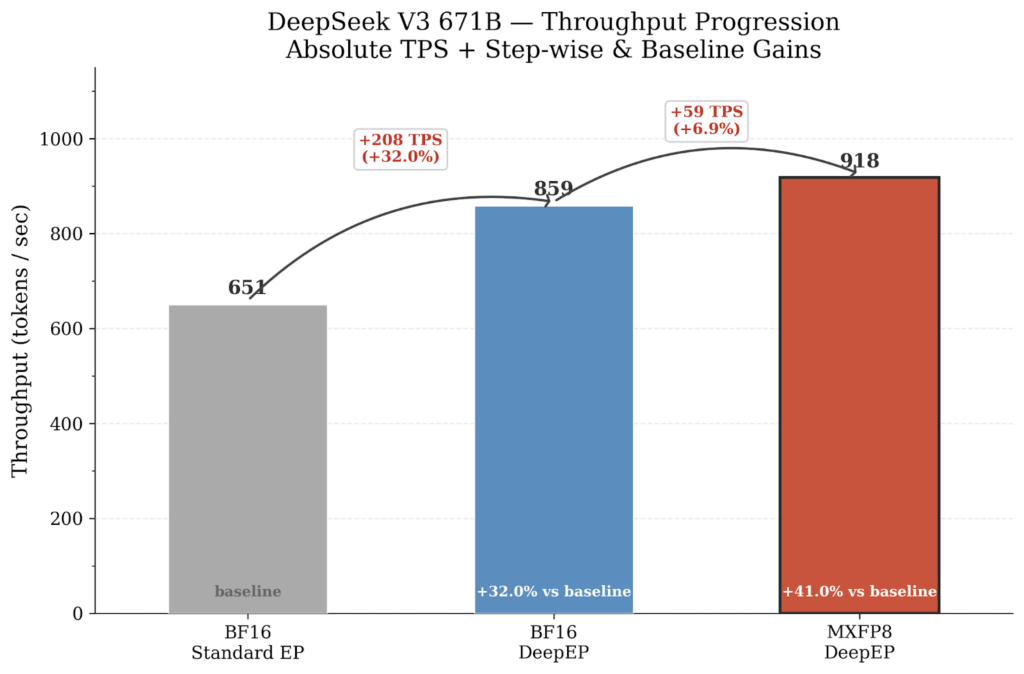
- DeepSeek-V3 671B: DeepEP alone yields 859 token/sec (+32...
Steelman: The study demonstrates that using Mixed-Precision Training (MXFP8) significantly improves machine learning model performance, particularly for large-scale tasks. The researchers highlight the potential for reduced computational costs and faster training times with this approach.
Patterns detected: ARC-0043 Motte-and-Bailey (The study emphasizes the benefits of MXFP8 without acknowledging its potential limitations or challenges).
Root Cause: The research reflects a paradigm of continuou...