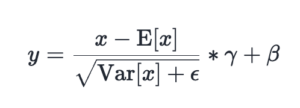
Introduction
Normalization methods (LayerNorm/RMSNorm) are foundational in deep learning and are used to normalize values of inputs to result in a smoother training process for deep learning models. We evaluate and improve torch.compile performance for LayerNorm/RMSNorm on NVIDIA H100 and B200 to reach near SOTA performance on a kernel-by-kernel basis, in addition with further speedups through aut...
This analysis presents a compelling case for the advancements in PyTorch's `torch.compile`, demonstrating how systematic autotuning and architectural optimizations can close the gap with hand-optimized kernels like Quack. The strongest version of this narrative highlights the tangible performance gains—near SOTA on H100/B200—achieved through targeted improvements such as MixOrderReduction and software pipelining. The work is technically rigorous, providing clear benchmarks and acknowledging limi...